
Mapeo por OCR interno
El desarrollo y la toma de datos mediante OCR interno es diferente con respecto al de ABBYY, ya que no es posible capturar cualquier campo que se encuentre en el documento, sino que se realiza solo el reconocimiento de aquellos documentos que posean código QR y códigos de barras.
 Nota:
Nota:
Es de suma importancia que los datos incrustados en el QR sean correctos y que el código tenga buena resolución para su correcta lectura.
Para comenzar es necesario crear una plantilla "Fantasma" dentro de la Plataforma Netcontent. Puede crear la plantilla y relacionarla con algún ".fcdot" de cualquier proyecto. Solo necesita que exista esta plantilla, sin importar los campos asociados a la misma, ni el orden.
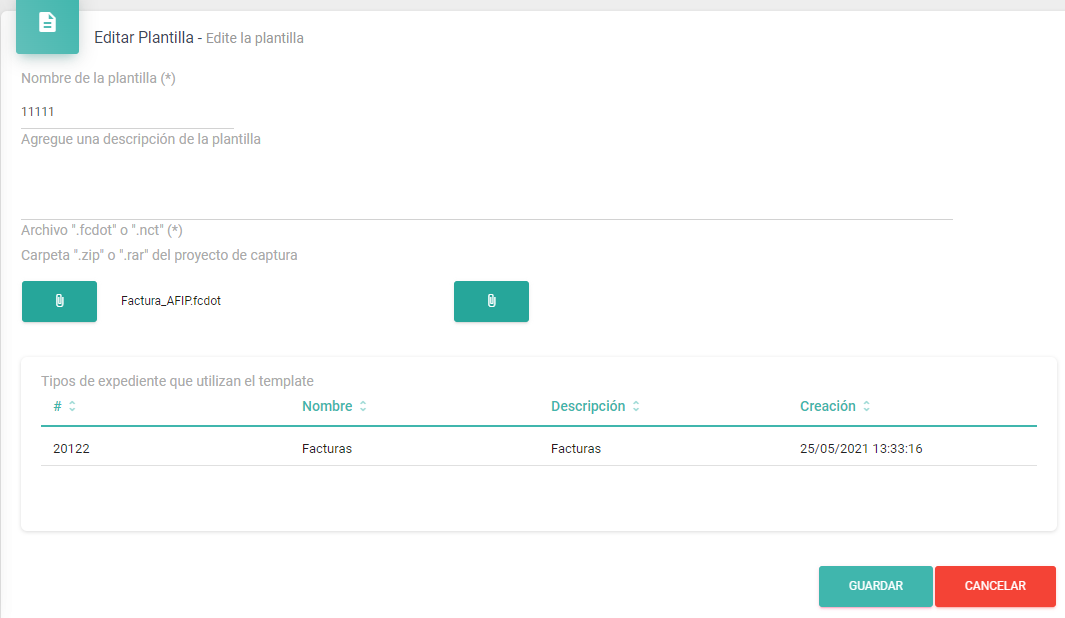
A modo de ejemplo puede ver una plantilla con el nombre "11111" y un .fcdot de otro proyecto.
Al finalizar estos pasos usted ya posee creada la "plantilla".
Luego, diríjase al apartado "Mapeo" dentro del Tipo de Expediente.
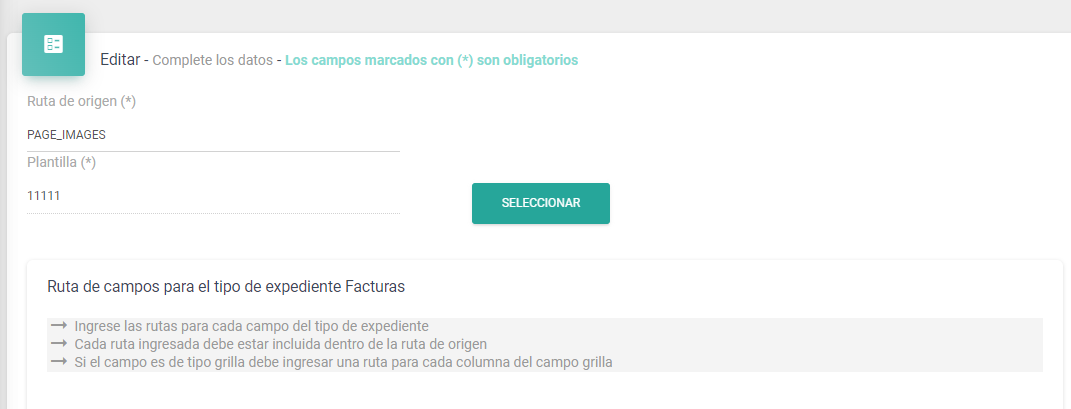
En los apartados:
Ruta de origen
Coloque "PAGE_IMAGES" (es importante previamente haber creado un campo de tipo "Adjuntos" en este Expediente con el nombre "PAGE_IMAGES" el cual Netcontent utiliza para tomarlo como base del documento para aplicar el OCR).
Plantilla
Seleccionamos la plantilla creada. Para el caso de ejemplo es "11111".
Ruta de Campos
Corresponde a como vienen predefinidos los campos dentro del QR. En el campo de "Factura" con formato tipo AFIP (La Administración Federal de Ingresos Públicos en Argentina. Varía dependiendo el país.) los campos se designan con la siguiente nomenclatura:
fecha: fecha de la factura.
Id Tributario: Id Tributario (el que la genera) de la factura.
ptoVta: punto de venta.
tipoCmp: fecha de la factura.
nroCmp: número de la factura.
importe: monto total de la factura.
moneda: moneda facturada.
ctz: tipo de cambia al Dolar.
nroDocRec: Id tributario (el que recibe) de la factura.
Es importante saber que no para todos los tipos de documentos los campos tienen el mismo código relacionado. Para saber que codificación poseen se recomienda hacer lo siguiente:
Primero, cree un campo de nombre "QR_TEXT" y otro llamado "BC_TEXT" para guardar el contenido de todos los códigos QR y de barra del documento capturado.
Luego, debe crear un flujo de captura de datos "Módulo de captura" referenciado al Tipo de Expediente en donde queremos aplicar el Tesseract.
Para el caso de captura por OCR Interno es de vital importancia en el clasificador tener la siguiente configuración:
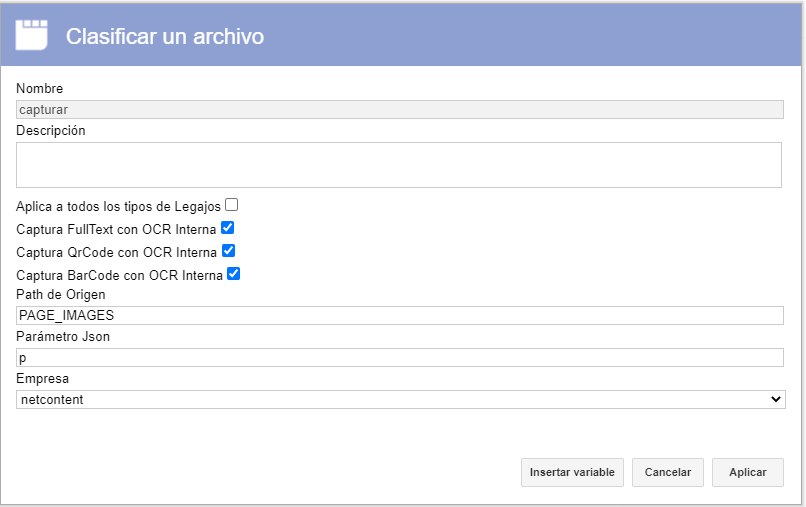
Nota:
El parámetro Json es el que se debe utilizar a nivel de captura para indicarle al OCR a partir de que momento se encuentran los datos que debe capturar.
Nota:
El Path de origen debe ser PAGE_IMAGES.
La letra "P" Corresponde a la decodificación del QR que nos arroja el Campo "QR_TEXT": de esta forma se ven los datos extraídos de un QR, depositado en ese campo:
{"state":null,"BarCodes":[{"Page":1,"Type":"QR_CODE","Data":"https://www.afip.gob.ar/fe/qr/?p=eyJ2ZXIiOjEsImZlY2hhIjoiMjAyMC0xMC0xMyIsImN1 aXQiOjMwMDAwMDAwMDA3LCJwdG9WdGEiOjEwLCJ0aXBvQ21wIjoxLCJucm9DbXAiO jk0LCJpbXBvcnRlIjoxMjEwMCwibW9uZWRhIjoiRE9MIiwiY3R6Ijo2NSwidGlwb0RvY1JlYyI 6ODAsIm5yb0RvY1JlYyI6MjAwMDAwMDAwMDEsInRpcG9Db2RBdXQiOiJFIiwiY29kQXV 0Ijo3MDQxNzA1NDM2NzQ3Nn0=","Points":[{"X":"125.0","Y":"3131.0"},{"X":"125.0","Y":"2880.0"},{"X":"376.0","Y":"2880.0"},{"X":"361.5","Y":"3116.5"}]}]}
Desde la configuración del Json le indica al sistema desde que punto va a leer los datos:
p=eyJ2ZXIiOjEsImZlY2hhIjoiMjAyMC0xMC0xMyIsImN1 aXQiOjMwMDAwMDAwMDA3LCJwdG9WdGEiOjEwLCJ0aXBvQ21wIjoxLCJucm9DbXAiO jk0LCJpbXBvcnRlIjoxMjEwMCwibW9uZWRhIjoiRE9MIiwiY3R6Ijo2NSwidGlwb0RvY1JlYyI 6ODAsIm5yb0RvY1JlYyI6MjAwMDAwMDAwMDEsInRpcG9Db2RBdXQiOiJFIiwiY29kQXV 0Ijo3MDQxNzA1NDM2NzQ3Nn0=
Esta codificación se encripta en Base64 format.
Desencriptando se obtiene:
{"ver":1,"fecha":"2020-10- 13","cuit":30000000007,"ptoVta":10,"tipoCmp":1,"nroCmp":94,"importe":12100,"mon eda":"DOL","ctz":65,"tipoDocRec":80,"nroDocRec":20000000001,"tipoCodAut":"E","co dAut":70417054367476}
Se puede ver la codificación de los campos y el valor relacionado con el documento en cuestión a modo de ejemplo.
De esta forma finaliza la captura de los datos mediante el método OCR interno en la plataforma Netcontent.
Creado con el Personal Edition de HelpNDoc: Producir eBooks para Kindle con facilidad