
Mapping of internal OCR
The internal OCR is capable of doing a full text OCR and capturing only documents containing QR codes and barcodes are recognized.
 Note:
Note:
It is crucial that the data embedded in the QR code is accurate and that the code has a high resolution for proper reading.
To begin, you need to create a "Phantom" template within the Netcontent Platform. You can create this template and link it to an ".fcdot" file from any project. The existence of this template is required, regardless of the associated fields or their order.
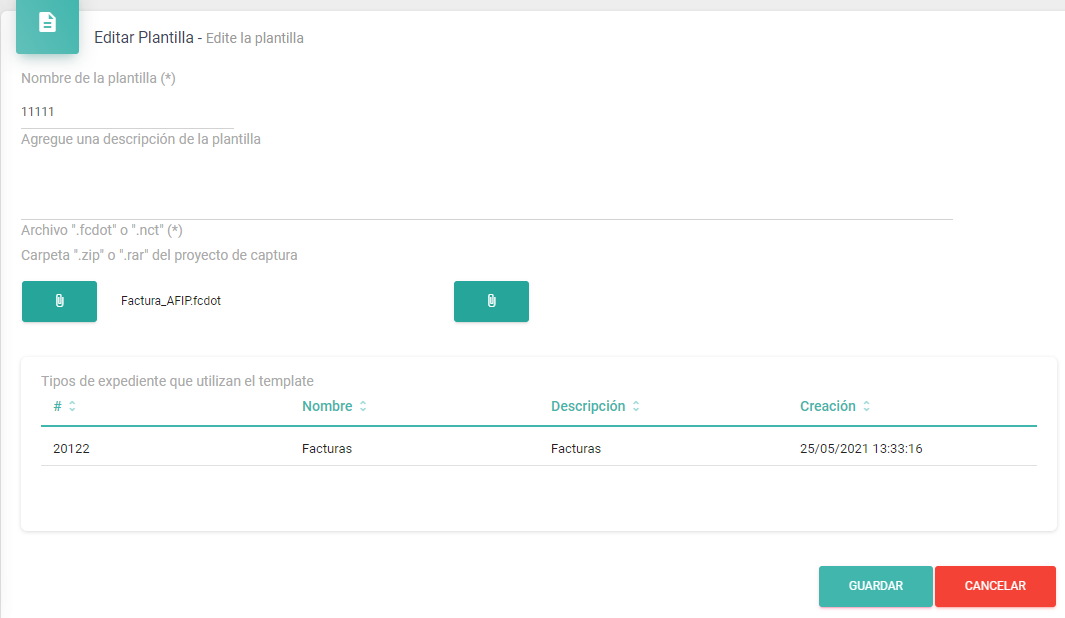
As an example, you can create a template named '11111' and link it to an .fcdot file from another project.
After completing these steps, the 'template' is now created.
Next, go to the 'Mapping' section within the File Type.
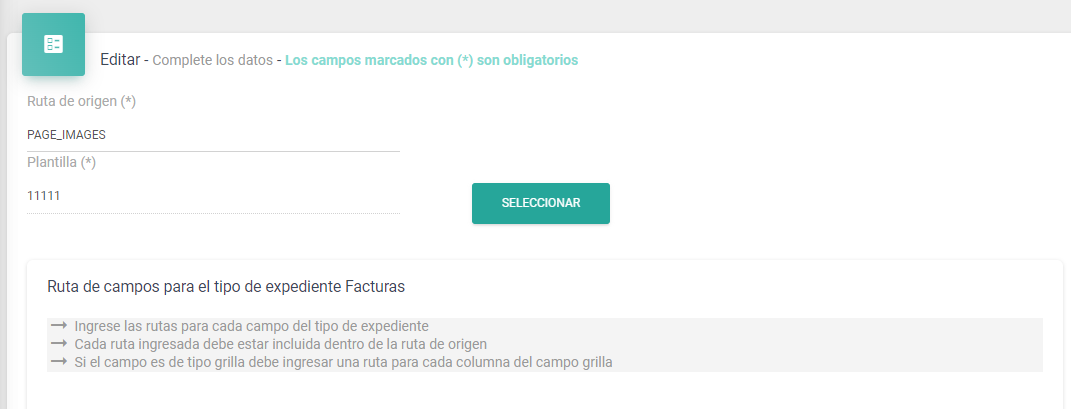
In the sections:
- Source Path:
Enter "PAGE_IMAGES" (it is important to have previously created an "Attachments" field in this File Type named "PAGE_IMAGES," which Tesseract uses as the document's base for applying OCR).
- Template:
Select the template created. In this example, it is "11111."
- Field Path:
This corresponds to how fields are predefined within the QR code. In an invoice field using the AFIP format (specific to Argentina's Federal Administration of Public Revenue, varying by country), the fields are designated with the following nomenclature:
- date: Date of the invoice.
- Tax ID: Tax ID of the issuer of the invoice.
- ptoVta: Point of sale.
- tipoCmp: Invoice type.
- nroCmp: Invoice number.
- amount: Total amount of the invoice.
- currency: Invoiced currency.
- exhange: Exchange rate to USD.
- nroDocRec: Tax ID of the recipient of the invoice.
It is important to note that not all document types have the same field codes. To identify the encoding, it is recommended to follow these steps:
- First, create a field named "QR_TEXT" and another named "BC_TEXT" to store the content of all QR codes and barcodes from the captured document.
- Then, create a data capture flow, "Capture Module," referenced to the File Type where you want to apply Tesseract..
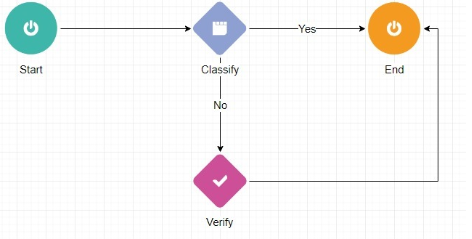
For data capture using Netcapture/Internal OCR, it is crucial to have the following configuration in the classifier:
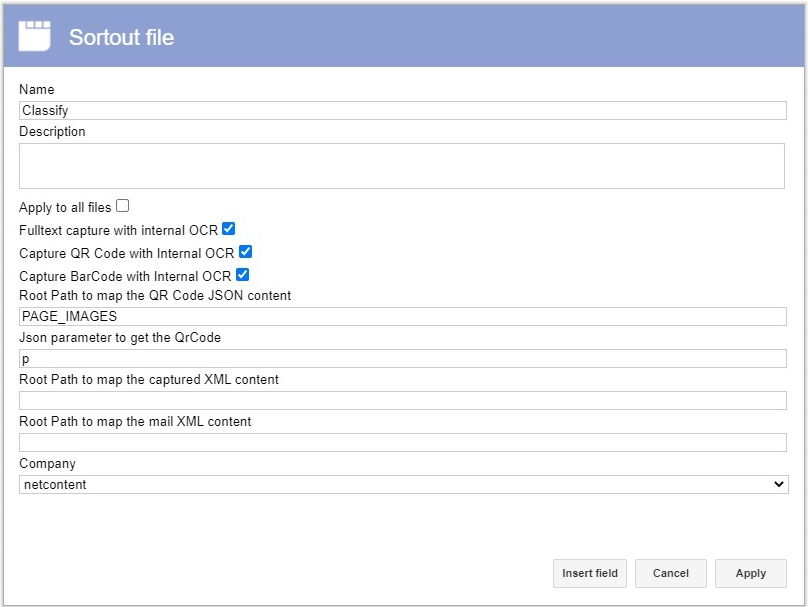
Note:
The JSON parameter is used at the capture level to indicate to the OCR the point at which the data to be captured is located.
Note:
The source path must be PAGE_IMAGES.
The letter 'P' corresponds to the decoding of the QR, which is output to the 'QR_TEXT' field. This is how the extracted data from a QR code is displayed in that field decodificación del QR que nos arroja el Campo "QR_TEXT": de esta forma se ven los datos extraídos de un QR, depositado en ese campo:
{"state":null,"BarCodes":[{"Page":1,"Type":"QR_CODE","Data":"https://www.afip.gob.ar/fe/qr/?p=eyJ2ZXIiOjEsImZlY2hhIjoiMjAyMi0wNC0xNSIsImN1aXQiOjIzMzA5ODk5MjI5LCJwdG9WdGEiOjUsInRpcG9DbXAiOjEsIm5yb0NtcCI6ODIsImltcG9ydGUiOjM3NDIzLjgxLCJtb25lZGEiOiJQRVMiLCJjdHoiOjEsInRpcG9Eb2NSZWMiOjgwLCJucm9Eb2NSZWMiOjMwNzEwNzgyMTg3LCJ0aXBvQ29kQXV0IjoiRSIsImNvZEF1dCI6NzIxNjk1NDc0OTQyNjd9","Points":[{"X":"125.0","Y":"3131.0"},{"X":"125.0","Y":"2880.0"},{"X":"376.0","Y":"2880.0"},{"X":"361.5","Y":"3116.5"}]}]}
- Within the JSON configuration, you specify the point from which the system will start reading the data:
p=eyJ2ZXIiOjEsImZlY2hhIjoiMjAyMi0wNC0xNSIsImN1aXQiOjIzMzA5ODk5MjI5LCJwdG9WdGEiOjUsInRpcG9DbXAiOjEsIm5yb0NtcCI6ODIsImltcG9ydGUiOjM3NDIzLjgxLCJtb25lZGEiOiJQRVMiLCJjdHoiOjEsInRpcG9Eb2NSZWMiOjgwLCJucm9Eb2NSZWMiOjMwNzEwNzgyMTg3LCJ0aXBvQ29kQXV0IjoiRSIsImNvZEF1dCI6NzIxNjk1NDc0OTQyNjd9
- This encoding is encrypted in Base64 format.
- When decrypted, it yields
{"ver":1,"fecha":"2022-04-15","cuit":0000000,"ptoVta":5,"tipoCmp":1,"nroCmp":82,"importe":37423.81,"moneda":"PES","ctz":1,"tipoDocRec":80,"nroDocRec":00000,"tipoCodAut":"E","codAut":000000}
You can see the field encoding and the values related to the document as an example.
This completes the data capture process using the Tesseract method in the Netcontent platform.
Created with the Personal Edition of HelpNDoc: Produce Kindle eBooks easily